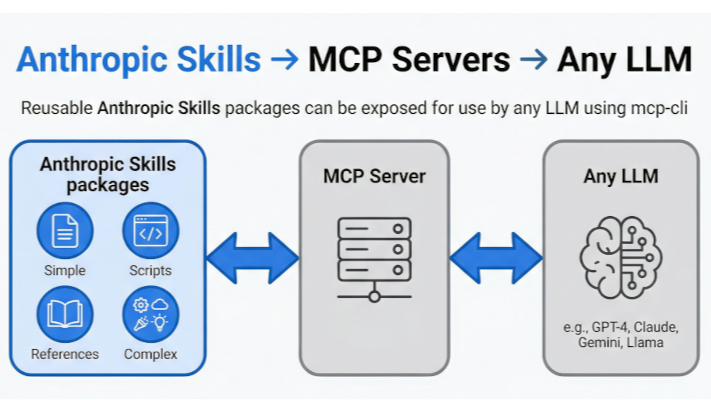
It's only been a year since Anthropic released Model Context Protocol (MCP), which became the standardised "interface" solution for AI models. Over the Christmas break, Anthropic Skills went live, and I believe they represent the missing piece for reliable AI automation in enterprise environments.
The Context Crisis
Large Language Models face a fundamental problem called "lost in the middle." When given massive amounts of context (think 100K+ tokens), they reliably remember the beginning and end of their input but struggle with critical instructions buried in the middle.
It's like a university student cramming for finals—you remember the first chapter you read at 8pm and the last page at 6am, but what you studied at 2am? That's a blur.
Mission-critical processes can't depend on whether the AI "remembers" the minor statements buried on page 47 of its context window.
Anthropic Skills (https://github.com/anthropics/skills) solve this through a simple pattern: instead of cramming everything into context, give the AI a library of concise "study notes" it can reference on demand.
Each skill is:
- Brief (typically 50-100 lines) focused documentation
- Task-specific guidance on one thing done well
- Progressive - can link to deeper documentation when needed
- Executable - can include helper scripts/tools
Rather than requiring massive context windows, models can access just the relevant skill when needed. Find documentation lacking? Update the skill for future runs.
Active vs Passive Skills
Skills may be used in two modes. The most basic approach is Passive mode, which only provides Markdown context on how to complete a task.
Active Skills allow the LLM to create and execute code. Originally, this is the pathway I was interested in as I created Semantic (no-code) workflows. My original work focussed on bash as it was easier of Deepseek to create code “first-time” for working with XML and JSON. This led to different thinking that I believe is a fundamental change for reliable, scalable and predictable Generative AI. The structure of Anthropic Skills libraries allows for the inclusion of pre-generated scripts for different tasks. The LLM can be reduced to deciding which script to execute rather than create black-box code on the fly. This has significant advantages.
Pre-generated scripts:
- Can be robust and put through testing processes prior to release
- Can incorporate validation and test-runner processes to run over task input and output
- Do not consume context as they are executed by the MCP server
- Are deterministic when AI content can never be
Although the actual skill itself is lightweight with what is exposed to the LLM, by leveraging pre-written deterministic helper scripts, we can build out the skill structure to include standard practice for code management and data validation as workflows tasks are executed.
The MCP Integration (And Why It Changes Everything)
Skills' progressive disclosure pattern is essentially identical to how MCP tools work. An LLM sees tool descriptions, chooses relevant ones, calls them, gets responses. This maps perfectly to Skills as an MCP server.
This means Skills can work with ANY MCP-compatible model, not just Claude.
The implications for enterprise AI maturity are significant:
- ✅ Governance: Every skill is documented, versioned, auditable
- ✅ Security: Code execution isolated in containers per skill
- ✅ Modularity: Workflows become very simple with LLMs decide which pre-written script to run. All execution is effectively managed through modular, versioned skills.
- ✅ Cost: Small, specialised models become viable
- ✅ Portability: Same skills work across different LLM providers
At this moment in time, not all small models can actually use MCP Skills effectively.
I tested 8 commonly used small models against both Python and bash skills in processing regulatory compliance documents. Each test involved progressive disclosure (read documentation → write code → execute → validate output).
The Results:
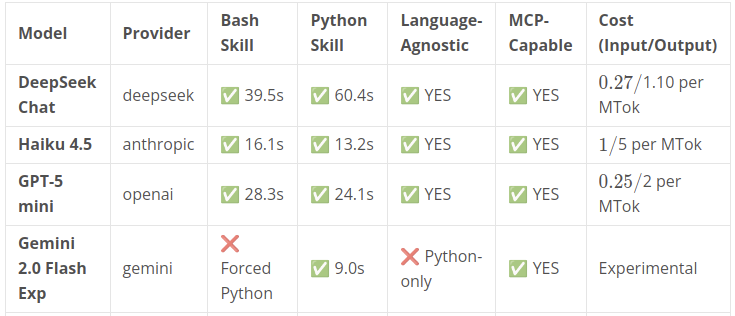
✅ MCP-Capable Models:
- Gemini 2.0 Flash Exp: 9.0s (FASTEST, but Python-only, FREE)
- Claude Haiku 4.5: 13.2s (fastest language-agnostic, $10/month for 1000 runs)
- GPT-5 mini: 24.1s (balanced, $3.25/month)
- DeepSeek Chat: 40-60s (cheapest at $1.82/month, NO API THROTTLING)
❌ Incompatible Models:
- GPT-4o-mini: Wrong output structure, can't follow schemas
- Kimi: Invented non-existent modules, failed completely after multiple retries
- Gemini Lite variants: Too weak for MCP patterns
Key Findings:
1. Language Bias exists
- Python-biased models (Gemini, Kimi) forced Python even when bash skills were specified
- Only 3 models (DeepSeek, Haiku, GPT-5 mini) were truly language-agnostic
From a scalable software perspective, the lighter the container, the faster its going to be and the fewer dependencies that can go wrong. Bash containers are ideal for large scale parallel tasking. The weighting toward Python for scripting was a surprising disappointment.
2. Speed ≠ Cost ≠ Capability
- Gemini: Fastest (9.0s) + Free, but Python-only
- DeepSeek: Slowest (40-60s) + Cheapest ($1.82/month) + No throttling + Language-agnostic
- For batch processing: DeepSeek's unlimited requests > speed
3. "Lite" Models Can't Handle MCP
- All "lite" variants failed (Gemini 2.5 Flash-Lite, 2.0 Flash-Lite)
- Cost reduction ≠ capability
The Enterprise Advantage
As I suggested previously, beyond cost savings, workflows leveraging Anthropic Skills enable something traditional approaches don't: proper governance.
Security & Isolation
- Each skill executes in its own container with access to a specific set of tools allowed for that task.
- Container Network access: Offering targetted Network Security controls as tasks require
- Audit: Every workflow execution may be logged for future review
Documentation as Code
- Skills ARE documentation (no docs drift)
- Version controlled (git)
- Test-driven (validate against actual usage)
- Peer reviewable (standard markdown)
- Transferable knowledge (not locked in tribal knowledge)
Model Portability
With proper skill design:
- Switch from GPT-5 mini to DeepSeek: Zero code changes
- Upgrade Claude version: Zero workflow changes
- Try new models: Test against existing skill library
Deterministic Reliability
- Executing Helper scripts allows for reliable testing and validation of input and output.
- Deterministic output
Why This Matters Now
Three converging trends make this the right moment:
1. Small Models Are Viable
- DeepSeek V3 matches GPT-4 quality at 1/50th the cost
- Qwen, Gemini, and other open/accessible models improving rapidly
- Enterprise can now run inference internally or choose providers strategically
2. MCP Standardisation
- One year in, MCP has critical mass with all providers now agreeing to support it
- Smaller models are being natively trained on using MCP
- Tools, libraries, patterns emerging
- Cross-provider portability is real
3. AI Governance Requirements
- Need for auditability, explainability, control
- Skills provide the structure regulations demand
Want to explore the code? → https://github.com/LaurieRhodes/mcp-cli-go/tree/main/docs/skills
- Log in to post comments